鐵達尼比賽就是提供乘客的個資,藉此來預測哪一種人存活率最高
例如老人女人小孩都有可能優先被排在救生艇,男人比較有英雄主義或是單身狗無牽無掛
就會先讓別人先上~當然我們不能做這麼粗淺的判斷
這也是kaggle 中的一個老比賽,算是資料科學入門的資料集
以下會分幾個階段來進行
這是老師筆記中的大綱
因為常常跟著老師的notebook 走的話,會有點不知道我們正在幹麻
所以還是介紹一下,一般機學習的步驟
這邊貼心再附一次老師的notebook
鐵達尼比賽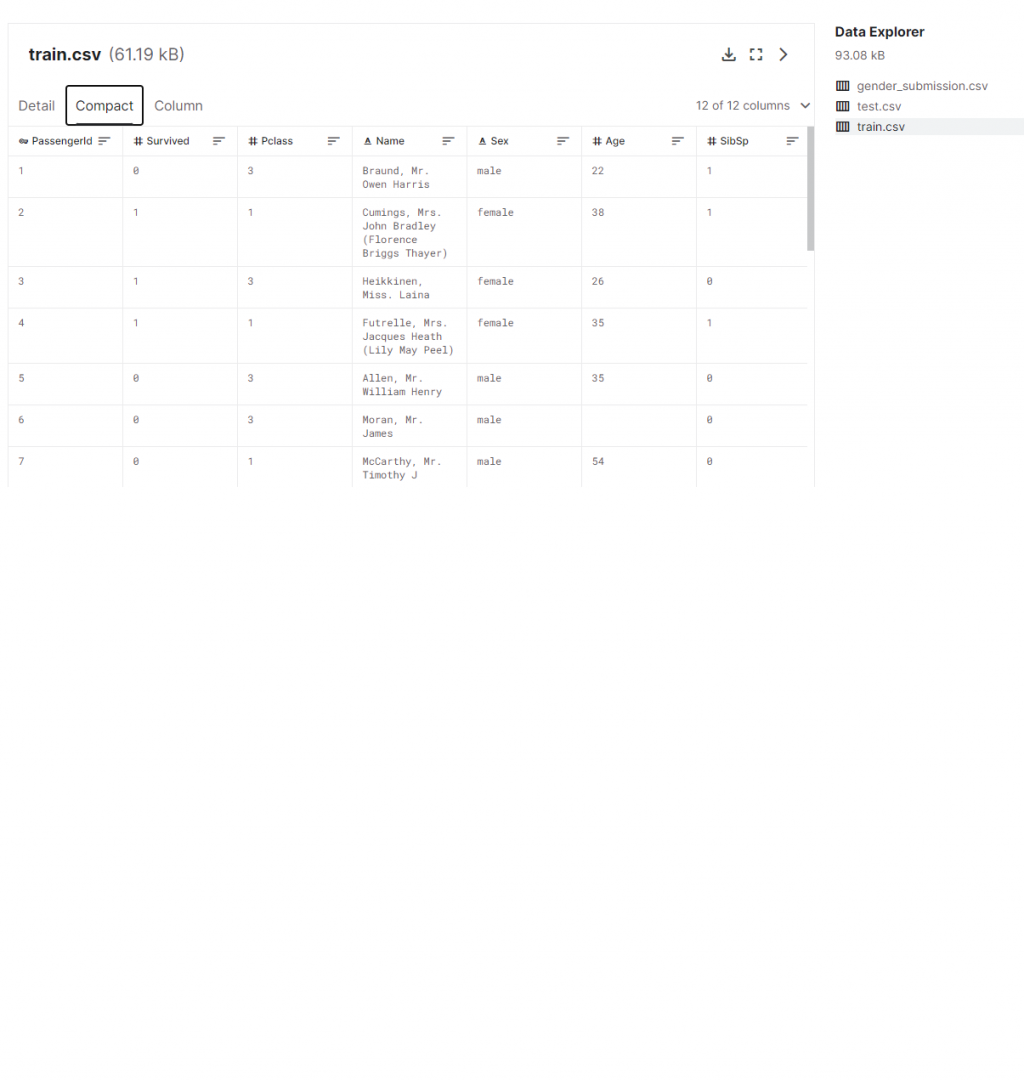
最重要的就是否存活,這也是我們要預測的,那其他欄位就看kaggle 的解釋,有些特別的kaggle 的解釋,例如兄弟姊妹關係,哪個港口,住什麼等級的客艙等等。
大概了解欄位之後,我們就要來看看資料是否「乾淨」
有沒有缺失值?
先來看一兩種補缺失值的方法
處理年齡(Age)的缺失值,使用中位數填充
df['Age'].fillna(df['Age'].median(), inplace=True)
處理登船港口(Embarked)的缺失值,使用眾數填充
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
inplace =True 就是修改原dataframe,而不是創一個新的物件
還有很多補充缺失值的方法,在這邊講師統一選擇用眾數來補充
當然這些可以按欄位來決定怎樣補較為合理~
先來看一下dataframe 提供什麼函數來幫我們處理眾數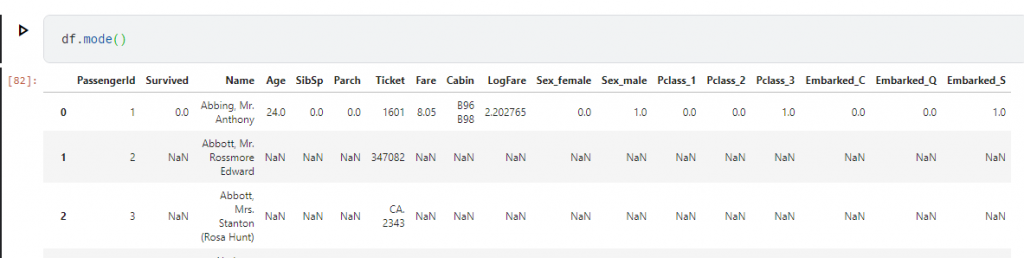
他會將每一列都幫我們取眾數,所以第2個row之後就不是我們要的
所以講師用df.mode().iloc[0]
來取第1個row
modes = df.mode().iloc[0]
df.fillna(modes, inplace=True)
這邊就是所有欄位都用他的眾數來填補的意思。
所以在這邊也是一個小細節:該怎麼填缺失值會更好呢?哪些欄位適合眾數?哪些適合平均?哪些又適合用標準差?優缺點各是什麼?
可以筆記一下,之後好好查更多資料來學習。
除了缺失值外,然後我們可以觀察一下特徵有沒有什麼「特性」
如果有怪怪的地方,是否也可以做一點處理
講師帶我們看了Fare這一欄(票價)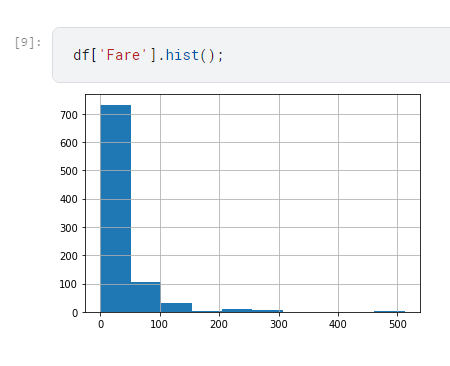
明顯的發現大家都買便宜的,極少數人買了超貴的
這些極值,在模型乘上係數的時候,就會對結果產生較大的影響
如前面提到假設我們的線是2次方程式 y= aX^2+bx+c
如果x 過大,那麼得到的y也會過大
所以講師提了一個取log 來使得資料較為平滑化的方法
如log10=1, log100=2 ,本來10跟100差90的,取log底數為10之後,就縮小到差1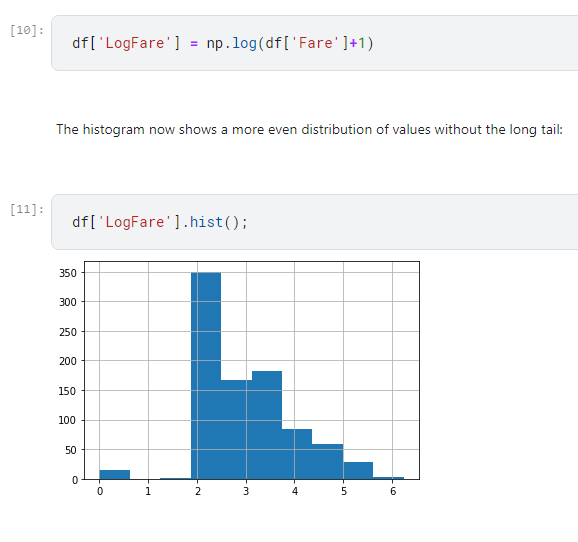
但這邊要注意,因為我們討論的是線性模型
所以這些工作就很重要
有的人會說,這些就是資料的特性阿,把他做這些「人工」處理不就也減少了資料特性?
說不定買豪華客艙的有優先使用救生艇的特權阿?
那這就跟模型的假設與設計比較相關,這個後續討論。
至少我們可以知道,做了「一些手段」對於某些「模型」有著較佳的效果
import matplotlib.pyplot as plt
import seaborn as sns
# 乘客年齡的直方圖
plt.figure(figsize=(8, 6))
sns.histplot(df['Age'], bins=30, kde=True)
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Distribution of Passenger Ages')
plt.show()
# 生存和死亡乘客的堆疊直方圖
plt.figure(figsize=(8, 6))
sns.histplot(data=df, x='Age', hue='Survived', bins=30, kde=True, multiple='stack')
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Distribution of Passenger Ages by Survival')
plt.show()
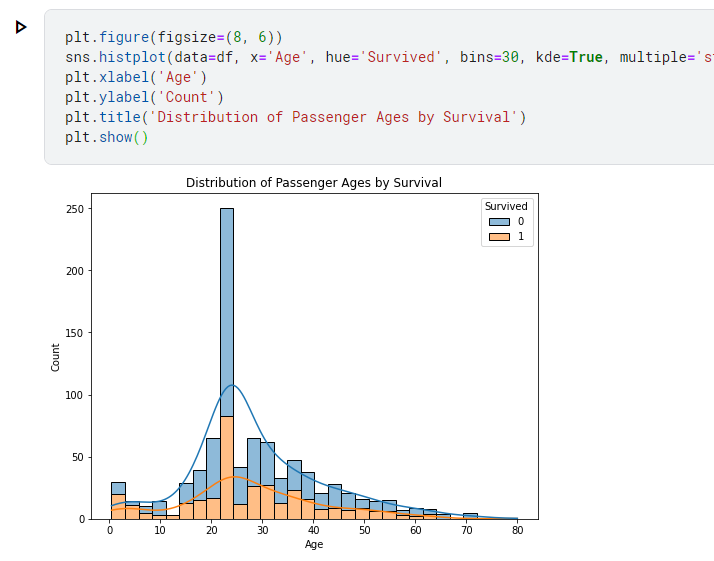
關於畫圖的方法,也可以多研究
這個圖大概能看出各年齡層死亡比例都蠻接近
比較有差異的是嬰幼兒,看得出來生存的機率很高。
有些欄位的資料是不能計算的
如sex:male/female,文字資料
pclass=1,2,3 (代表類別 ,沒有大小意義)
Embarked:哪個港口上船的,文字資料
為了處理這個問題,我們可以使用one-hot encoding,這就是說把每一個類別視為0 或1
如果有多個類別,就創造多個欄位,讓他們分別用0或1 代表
例如pclass 有3個類別,就會用3個欄位來表示,pclass_1, pclass_2,pclass_3
df = pd.get_dummies(df, columns=["Sex","Pclass","Embarked"])

可以看到我們的資料又被我們改來改去的變成新樣貌了!
首先我們要先來設定目標變量(也就是應變數,個人不喜歡這個名字)是哪個欄位
沒錯,是Survived對吧
from torch import tensor
t_dep = tensor(df.Survived)
這邊我們創了一個tensor,把dataframe 轉化為tensor,用t_dep來存。
indep_cols = ['Age', 'SibSp', 'Parch', 'LogFare'] + added_cols
added_cols = ['Sex_male', 'Sex_female', 'Pclass_1', 'Pclass_2', 'Pclass_3', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
t_indep = tensor(df[indep_cols].values, dtype=torch.float)
這邊把我們選取的欄位(獨立變數)也轉化為tensor,存在t_indep裡面
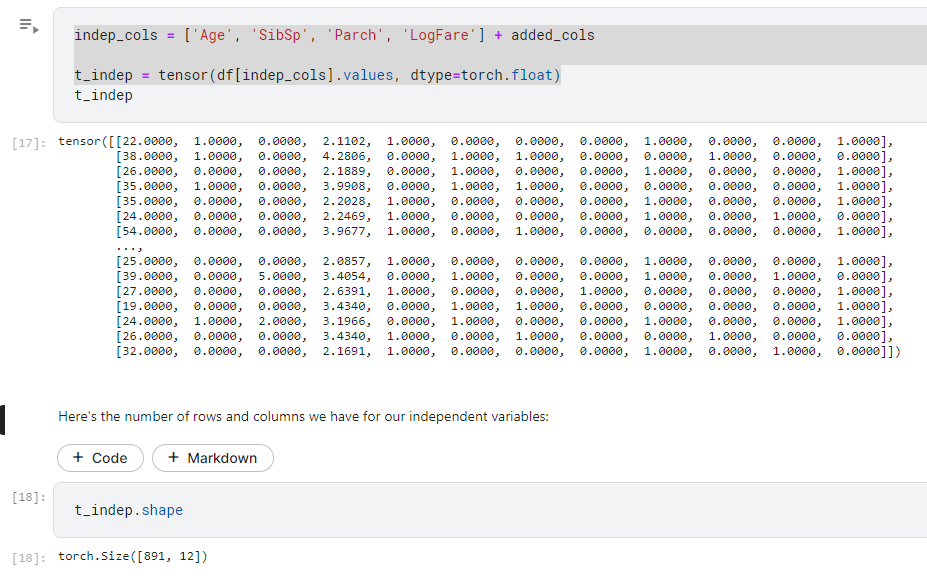
這邊就可以看到我們的獨立變量,包含剛才的獨熱變碼後的值
接下來就開始設定模型了,下篇繼續!

